JIT 编译器(just in time 即时编译器),当虚拟机发现某个方法或代码块运行特别频繁时,就会把这些代码认定为(Hot Spot Code 热点代码),为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各层次的优化,完成这项任务的正是 JIT 编译器。
JIT 的工作原理
JIT 编译
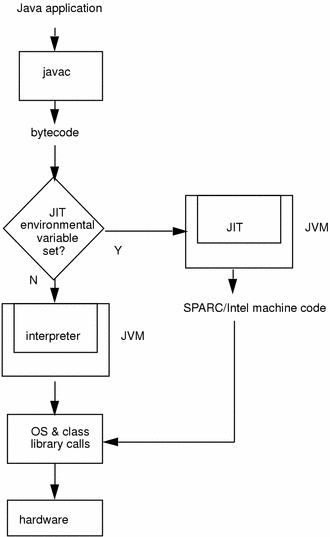
对于 Java 代码,刚开始都是被编译器编译成字节码文件,然后字节码文件会被交由 JVM 解释执行,所以可以说 Java 本身是一种半编译半解释执行的语言。
当 JIT 编译启用时(默认是启用的),JVM 读入.class 文件解释后,将其发给 JIT 编译器。JIT 编译器将字节码编译成本机机器代码。
通常 Javac 将程序源码编译,转换成 Java 字节码,JVM 通过解释字节码将其翻译成相应的机器指令,逐条读入,逐条解释翻译。 经过解释运行,其运行速度必定会比可运行的二进制字节码程序慢。为了提高运行速度,引入了 JIT 技术。
在执行时 JIT 会把翻译过的机器码保存起来,已备下次使用,因此从理论上来说,采用该 JIT 技术能够,能够接近曾经纯编译技术。
JIT 编译器
HotSpot 内置了两个编译器,分别是 Client Compiler 和 Server Complier,或者简称为 C1 和 C2 编译器。同时用到两个编译器的分层编译(Tiered Compilation)策略,使用后,C1 和 C2 同时工作,有些代码可能多次编译,用 C1 获取更高的编译速度,C2 获取更好的编译质量:
-
第 0 层,程序解释执行,解释器不开启性能监视功能(Profiling),可触发第 1 层编译。
-
第 1 层,也称为 C1 编译,将字节码编译成本地代码,进行简单、可靠的优化,若有必要将加入性能监控的逻辑。
-
第 2 层,也称为 C2 编译,也是将字节码编译成为本地代码,但是会启动一些编译耗时较长的优化,甚至会根据性能监控进行一些不可靠的激进优化。
编译对象和触发条件
在运行过程中被即时编译器编译的“热点代码”有两类,即:
-
被多次调用的方法
-
被多次执行的循环体
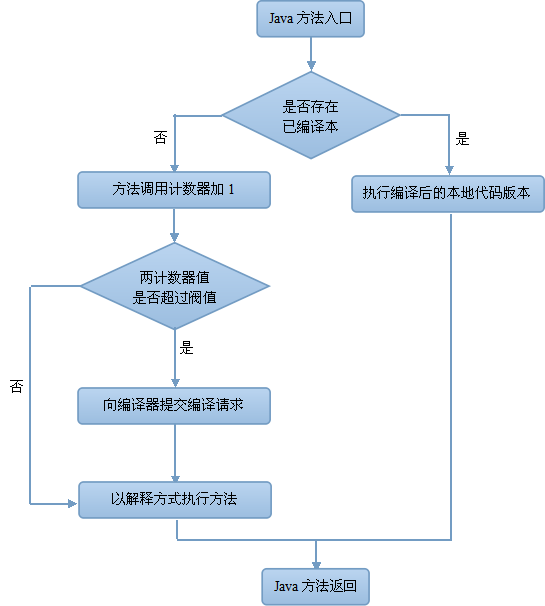
对第一种情况,由于是方法调用触发的编译,因此编译器会以整个方法作为编译对象,即标准的 JIT 编译方式。后一种,虽然是循环体触发的编译动作,但编译器依然按照整个方法(而不是单独的循环体)作为编译对象。这种编译方式称为栈上替换(On Stack Replacement,简称为 OSR 编译)。
判断一段代码是不是热点代码,是不是需要触发即时编译,这样的行为称为热点探测(Hot Spot Detection),目前有两种方法:
-
基于采样的热点探测:采用这样的方法的虚拟机会周期性的检查各个线程的栈顶,如果发现某个(或某些)方法经常出现在栈顶,那这个方法就是“热点方法”。其好处就是实现简单、高效,还可以很容易的获取方法调用关系(将调用栈展开即可),缺点是很难精确的确认一个方法的热度,容易因为受到线程阻塞或别的外界因素的影响。
-
基于计数器的热点探测:为每一个方法(甚至是代码块)建立计数器,统计方法的执行次数,超过一定的阈值就认为是“热点方法”。缺点是实现起来更麻烦,需要为每个方法建立并维护计数器,并且不能直接获取到方法的调用关系,优点是它的统计结果相对来说更加精确和严谨。
HotSpot 虚拟机使用第二种,它为每个方法准备了两类计数器:方法调用计数器(Invocation Counter)和回边计数器(Back Edge Counter,用于统计一个方法中循环体代码执行的次数)。
参考
https://www.jianshu.com/p/ae0d47e770f0
https://blog.csdn.net/shengzhu1/article/details/73281722